こんにちは。takapy(@takapy0210)です。
本エントリは言語処理100本ノック2020の8章を解いてみたので、それの備忘です。
簡単な解説をつけながら紹介していきます。
ネット上に掲載されている解答例はPytorchによる解法が多かったので、TensorFlowを用いて解いてみました。
コードはGithubに置いてあります。
第8章: ニューラルネット
第6章で取り組んだニュース記事のカテゴリ分類を題材として,ニューラルネットワークでカテゴリ分類モデルを実装する.なお,この章ではPyTorch, TensorFlow, Chainerなどの機械学習プラットフォームを活用せよ
- 70. 単語ベクトルの和による特徴量
- 71. 単層ニューラルネットワークによる予測
- 72. 損失と勾配の計算
- 73. 確率的勾配降下法による学習
- 74. 正解率の計測
- 75. 損失と正解率のプロット / 76. チェックポイント / 77. ミニバッチ化
- 79. 多層ニューラルネットワーク
70. 単語ベクトルの和による特徴量
SWEMを用いて単語の平均ベクトルを計算しています.
SWEMのコード部分にはこちらのGithubに掲載しています.
""" 70. 単語ベクトルの和による特徴量 問題50で構築した学習データ,検証データ,評価データを行列・ベクトルに変換したい. i番目の事例の記事見出しを,その見出しに含まれる単語のベクトルの平均で表現したものがxiである.今回は単語ベクトルとして,問題60でダウンロードしたものを用いればよい. 以下の行列・ベクトルを作成し,ファイルに保存せよ. 学習データの特徴量行列: Xtrain∈ℝNt×d 学習データのラベルベクトル: Ytrain∈ℕNt 検証データの特徴量行列: Xvalid∈ℝNv×d 検証データのラベルベクトル: Yvalid∈ℕNv 評価データの特徴量行列: Xtest∈ℝNe×d 評価データのラベルベクトル: Ytest∈ℕNe """ import pandas as pd from gensim.models import KeyedVectors import texthero as hero from swem import SWEM def load_data() -> dict: """データの読み込み""" # 読み込むファイルを定義 inputs = { 'train': '../chapter6/train.txt', 'valid': '../chapter6/valid.txt', 'test': '../chapter6/test.txt', } dfs = {} use_cols = ['title', 'category'] for k, v in inputs.items(): dfs[k] = pd.read_csv(v, sep='\t') dfs[k] = dfs[k][use_cols] return dfs def preprocess(text) -> str: """前処理""" clean_text = hero.clean(text, pipeline=[ hero.preprocessing.fillna, hero.preprocessing.lowercase, hero.preprocessing.remove_digits, hero.preprocessing.remove_punctuation, hero.preprocessing.remove_diacritics, hero.preprocessing.remove_stopwords ]) return clean_text if __name__ == "__main__": # chapter6で生成したデータを読み込む dfs = load_data() # 事前学習済みモデルのロード # ref. https://radimrehurek.com/gensim/models/word2vec.html#usage-examples model = KeyedVectors.load_word2vec_format('../chapter7/GoogleNews-vectors-negative300.bin.gz', binary=True) # 前処理 dfs['train']['title'] = dfs['train'][['title']].apply(preprocess) dfs['valid']['title'] = dfs['valid'][['title']].apply(preprocess) dfs['test']['title'] = dfs['test'][['title']].apply(preprocess) # 説明変数の生成(SWEMの計算) swem = SWEM(model) X_train = swem.calculate_emb(df=dfs['train'], col='title', window=3, swem_type=1) X_valid = swem.calculate_emb(df=dfs['valid'], col='title', window=3, swem_type=1) X_test = swem.calculate_emb(df=dfs['test'], col='title', window=3, swem_type=1) # 目的変数の生成 y_train = dfs['train']['category'].map({'b': 0, 'e': 1, 't': 2, 'm': 3}) y_valid = dfs['valid']['category'].map({'b': 0, 'e': 1, 't': 2, 'm': 3}) y_test = dfs['test']['category'].map({'b': 0, 'e': 1, 't': 2, 'm': 3}) # 保存 X_train.to_pickle('X_train.pkl') X_valid.to_pickle('X_valid.pkl') X_test.to_pickle('X_test.pkl') y_train.to_pickle('y_train.pkl') y_valid.to_pickle('y_valid.pkl') y_test.to_pickle('y_test.pkl')
71. 単層ニューラルネットワークによる予測
TensorFlowを用いて、単層ニューラルネットワークを構築し、指示された内容を計算しています.
""" 71. 単層ニューラルネットワークによる予測 問題70で保存した行列を読み込み,学習データについて以下の計算を実行せよ. ŷ 1=softmax(x1W),Ŷ =softmax(X[1:4]W) ただし,softmaxはソフトマックス関数,X[1:4]∈ℝ4×dは特徴ベクトルx1,x2,x3,x4を縦に並べた行列である. X[1:4]=⎛⎝⎜⎜⎜⎜x1x2x3x4⎞⎠⎟⎟⎟⎟ 行列W∈ℝd×Lは単層ニューラルネットワークの重み行列で,ここではランダムな値で初期化すればよい(問題73以降で学習して求める). なお,ŷ 1∈ℝLは未学習の行列Wで事例x1を分類したときに,各カテゴリに属する確率を表すベクトルである. 同様に,Ŷ ∈ℝn×Lは,学習データの事例x1,x2,x3,x4について,各カテゴリに属する確率を行列として表現している. """ import pandas as pd import tensorflow as tf class SimpleNet: def __init__(self, feature_dim, target_dim): self.input = tf.keras.layers.Input(shape=(feature_dim), name='input') self.output = tf.keras.layers.Dense(target_dim, activation='softmax', name='output') def build(self): input_layer = self.input output_layer = self.output(input_layer) model = tf.keras.models.Model(inputs=input_layer, outputs=output_layer) return model if __name__ == "__main__": X_train = pd.read_pickle('X_train.pkl') model = SimpleNet(X_train.shape[1], 4).build() print(model(X_train.values[:1])) print(model(X_train.values[:4]))
実行結果
tf.Tensor([[0.2661007 0.25712514 0.2329659 0.2438082 ]], shape=(1, 4), dtype=float32) tf.Tensor( [[0.2661007 0.25712514 0.23296592 0.2438082 ] [0.27437785 0.25097498 0.23388673 0.24076048] [0.27228996 0.25715688 0.234876 0.23567708] [0.27745858 0.25357178 0.22825074 0.24071899]], shape=(4, 4), dtype=float32)
72. 損失と勾配の計算
損失の計算にはtf.keras.losses.CategoricalCrossentropy()を使っています.
""" 72. 損失と勾配の計算 学習データの事例x1と事例集合x1,x2,x3,x4に対して,クロスエントロピー損失と,行列Wに対する勾配を計算せよ.なお,ある事例xiに対して損失は次式で計算される. li=−log[事例xiがyiに分類される確率] ただし,事例集合に対するクロスエントロピー損失は,その集合に含まれる各事例の損失の平均とする. """ import pandas as pd import tensorflow as tf from tensorflow.keras.utils import to_categorical class SimpleNet: def __init__(self, feature_dim, target_dim): self.input = tf.keras.layers.Input(shape=(feature_dim), name='input') self.output = tf.keras.layers.Dense(target_dim, activation='softmax', name='output') def build(self): input_layer = self.input output_layer = self.output(input_layer) model = tf.keras.models.Model(inputs=input_layer, outputs=output_layer) return model if __name__ == "__main__": # データのロード X_train = pd.read_pickle('X_train.pkl') y_train = pd.read_pickle('y_train.pkl') # モデル構築 model = SimpleNet(X_train.shape[1], len(y_train.unique())).build() preds = model(X_train.values[:4]) # 目的変数をone-hotに変換 y_true = to_categorical(y_train) y_true = y_true[:4] # 計算 cce = tf.keras.losses.CategoricalCrossentropy() print(cce(y_true, preds.numpy()).numpy())
実行結果
1.4818511
73. 確率的勾配降下法による学習
ラベルはone-hotに変換していないので、lossにはSparseCategoricalCrossentropy()を用いています.
""" 73. 確率的勾配降下法による学習 確率的勾配降下法(SGD: Stochastic Gradient Descent)を用いて,行列Wを学習せよ.なお,学習は適当な基準で終了させればよい(例えば「100エポックで終了」など) """ import pandas as pd import tensorflow as tf class SimpleNet: def __init__(self, feature_dim, target_dim): self.input = tf.keras.layers.Input(shape=(feature_dim), name='input') self.output = tf.keras.layers.Dense(target_dim, activation='softmax', name='output') def build(self): input_layer = self.input output_layer = self.output(input_layer) model = tf.keras.models.Model(inputs=input_layer, outputs=output_layer) return model if __name__ == "__main__": # データのロード X_train = pd.read_pickle('X_train.pkl') y_train = pd.read_pickle('y_train.pkl') # モデル構築 model = SimpleNet(X_train.shape[1], len(y_train.unique())).build() opt = tf.optimizers.SGD() model.compile( optimizer=opt, loss=tf.keras.losses.SparseCategoricalCrossentropy() ) # 学習 tf.keras.backend.clear_session() model.fit( X_train, y_train, epochs=50, batch_size=32, verbose=1 ) # モデルの保存 model.save("tf_model.h5")
実行結果
Epoch 1/50 334/334 [==============================] - 0s 1ms/step - loss: 1.1319 Epoch 2/50 334/334 [==============================] - 0s 1ms/step - loss: 1.1315 ... Epoch 48/50 334/334 [==============================] - 0s 1ms/step - loss: 1.1124 Epoch 49/50 334/334 [==============================] - 1s 2ms/step - loss: 1.1121 Epoch 50/50 334/334 [==============================] - 0s 1ms/step - loss: 1.1118
74. 正解率の計測
推論結果に関しては、そのままだと各クラスの確率が返却されるので、np.argmaxで一番確率の高いクラスを取得して正解率を計算しています.
""" 74. 正解率の計測 問題73で求めた行列を用いて学習データおよび評価データの事例を分類したとき,その正解率をそれぞれ求めよ. """ import pandas as pd import numpy as np import tensorflow as tf from sklearn.metrics import accuracy_score class SimpleNet: def __init__(self, feature_dim, target_dim): self.input = tf.keras.layers.Input(shape=(feature_dim), name='input') self.output = tf.keras.layers.Dense(target_dim, activation='softmax', name='output') def build(self): input_layer = self.input output_layer = self.output(input_layer) model = tf.keras.models.Model(inputs=input_layer, outputs=output_layer) return model if __name__ == "__main__": # データのロード X_train = pd.read_pickle('X_train.pkl') y_train = pd.read_pickle('y_train.pkl') X_valid = pd.read_pickle('X_valid.pkl') y_valid = pd.read_pickle('y_valid.pkl') # モデルのロード model = tf.keras.models.load_model("tf_model.h5") # 推論 y_train_preds = model.predict(X_train, verbose=1) y_valid_preds = model.predict(X_valid, verbose=1) # 一番確率の高いクラスを取得 y_train_preds = np.argmax(y_train_preds, 1) y_valid_preds = np.argmax(y_valid_preds, 1) # 正解率を出力 print(f'Train Accuracy: {accuracy_score(y_train, y_train_preds)}') print(f'Valid Accuracy: {accuracy_score(y_valid, y_valid_preds)}')
実行結果
334/334 [==============================] - 0s 695us/step 42/42 [==============================] - 0s 680us/step Train Accuracy: 0.5493815592203898 Valid Accuracy: 0.5374812593703149
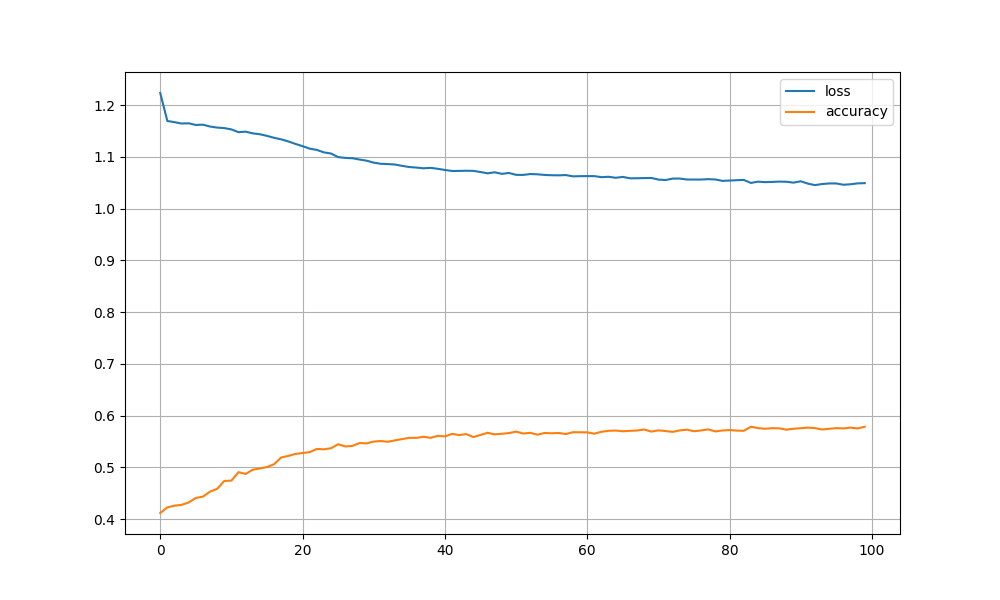
75. 損失と正解率のプロット / 76. チェックポイント / 77. ミニバッチ化
3つ一気に実装しています.
""" 75. 損失と正解率のプロット 問題73のコードを改変し,各エポックのパラメータ更新が完了するたびに,訓練データでの損失,正解率,検証データでの損失,正解率をグラフにプロットし,学習の進捗状況を確認できるようにせよ. 76. チェックポイント 問題75のコードを改変し,各エポックのパラメータ更新が完了するたびに,チェックポイント(学習途中のパラメータ(重み行列など)の値や最適化アルゴリズムの内部状態)をファイルに書き出せ. 77. ミニバッチ化 問題76のコードを改変し,B事例ごとに損失・勾配を計算し,行列Wの値を更新せよ(ミニバッチ化).Bの値を1,2,4,8,…と変化させながら,1エポックの学習に要する時間を比較せよ. """ import pandas as pd import matplotlib.pyplot as plt import tensorflow as tf class SimpleNet: def __init__(self, feature_dim, target_dim): self.input = tf.keras.layers.Input(shape=(feature_dim), name='input') self.output = tf.keras.layers.Dense(target_dim, activation='softmax', name='output') def build(self): input_layer = self.input output_layer = self.output(input_layer) model = tf.keras.models.Model(inputs=input_layer, outputs=output_layer) return model if __name__ == "__main__": # データのロード X_train = pd.read_pickle('X_train.pkl') y_train = pd.read_pickle('y_train.pkl') # モデル構築 model = SimpleNet(X_train.shape[1], len(y_train.unique())).build() opt = tf.optimizers.SGD() model.compile( optimizer=opt, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy'] ) # チェックポイント checkpoint_path = 'ck_tf_model.h5' cb_checkpt = tf.keras.callbacks.ModelCheckpoint( checkpoint_path, monitor='loss', save_best_only=True, mode='min', verbose=1 ) # 学習 tf.keras.backend.clear_session() history = model.fit( X_train, y_train, epochs=100, batch_size=32, callbacks=[cb_checkpt], verbose=1 ) # 学習曲線の保存 pd.DataFrame(history.history).plot(figsize=(10, 6)) plt.grid(True) plt.savefig("learning_curves.png")
実行結果
Epoch 1/100 334/334 [==============================] - 1s 918us/step - loss: 1.2599 - accuracy: 0.4254 Epoch 00001: loss improved from inf to 1.21570, saving model to ck_tf_model.h5 Epoch 2/100 334/334 [==============================] - 0s 968us/step - loss: 1.1667 - accuracy: 0.4256 Epoch 00002: loss improved from 1.21570 to 1.16557, saving model to ck_tf_model.h5 ... Epoch 00098: loss improved from 1.11229 to 1.11196, saving model to ck_tf_model.h5 Epoch 99/100 334/334 [==============================] - 0s 1ms/step - loss: 1.1190 - accuracy: 0.5538 Epoch 00099: loss improved from 1.11196 to 1.11144, saving model to ck_tf_model.h5 Epoch 100/100 334/334 [==============================] - 0s 1ms/step - loss: 1.1135 - accuracy: 0.5518 Epoch 00100: loss improved from 1.11144 to 1.11131, saving model to ck_tf_model.h5
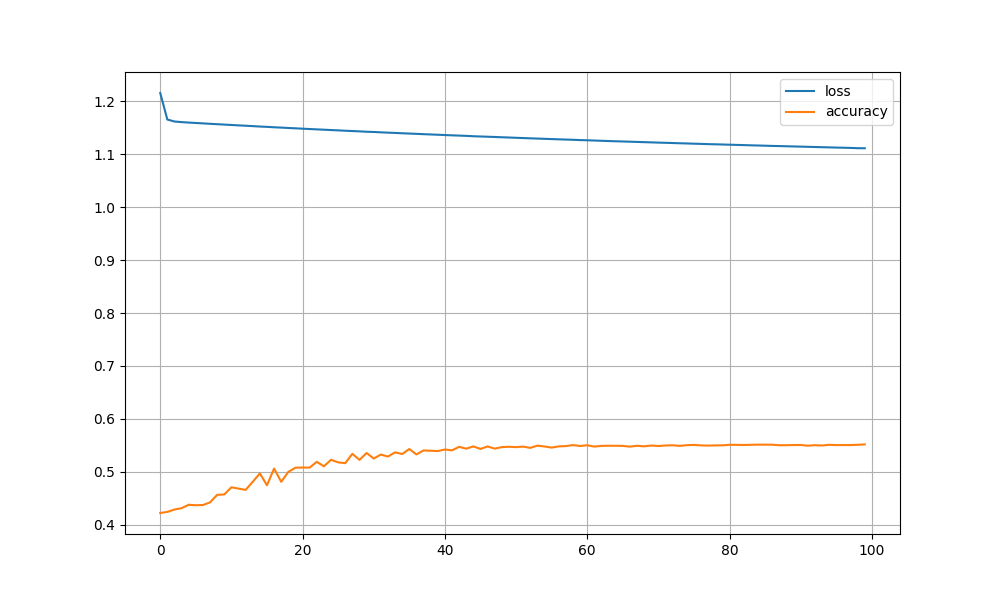
79. 多層ニューラルネットワーク
単層のときより、若干スコアが改善しました.
""" 79. 多層ニューラルネットワーク 問題78のコードを改変し,バイアス項の導入や多層化など,ニューラルネットワークの形状を変更しながら,高性能なカテゴリ分類器を構築せよ. """ import numpy as np import pandas as pd import matplotlib.pyplot as plt import tensorflow as tf from sklearn.metrics import accuracy_score class MLPNet: def __init__(self, feature_dim, target_dim): self.input = tf.keras.layers.Input(shape=(feature_dim), name='input') self.hidden1 = tf.keras.layers.Dense(128, activation='relu', name='hidden1') self.hidden2 = tf.keras.layers.Dense(32, activation='relu', name='hidden2') self.dropout = tf.keras.layers.Dropout(0.2, name='dropout') self.output = tf.keras.layers.Dense(target_dim, activation='softmax', name='output') def build(self): input_layer = self.input hidden1 = self.hidden1(input_layer) dropout1 = self.dropout(hidden1) hidden2 = self.hidden2(dropout1) dropout2 = self.dropout(hidden2) output_layer = self.output(dropout2) model = tf.keras.models.Model(inputs=input_layer, outputs=output_layer) return model if __name__ == "__main__": # データのロード X_train = pd.read_pickle('X_train.pkl') y_train = pd.read_pickle('y_train.pkl') X_valid = pd.read_pickle('X_valid.pkl') y_valid = pd.read_pickle('y_valid.pkl') # モデル構築 model = MLPNet(X_train.shape[1], len(y_train.unique())).build() opt = tf.optimizers.SGD() model.compile( optimizer=opt, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy'] ) # チェックポイント checkpoint_path = 'ck_tf_model.h5' cb_checkpt = tf.keras.callbacks.ModelCheckpoint( checkpoint_path, monitor='loss', save_best_only=True, mode='min', verbose=1 ) # 学習 tf.keras.backend.clear_session() history = model.fit( X_train, y_train, epochs=100, batch_size=32, callbacks=[cb_checkpt], verbose=1 ) # 推論 y_train_preds = model.predict(X_train, verbose=1) y_valid_preds = model.predict(X_valid, verbose=1) # 一番確率の高いクラスを取得 y_train_preds = np.argmax(y_train_preds, 1) y_valid_preds = np.argmax(y_valid_preds, 1) # 正解率を出力 print(f'Train Accuracy: {accuracy_score(y_train, y_train_preds)}') print(f'Valid Accuracy: {accuracy_score(y_valid, y_valid_preds)}') # 学習曲線の保存 pd.DataFrame(history.history).plot(figsize=(10, 6)) plt.grid(True) plt.savefig("learning_curves.png")
実行結果
... Train Accuracy: 0.5812406296851574 Valid Accuracy: 0.5704647676161919