
こんにちは。takapy(@takapy0210)です。
本記事はコネヒト Advent Calendar 2020の10日目の記事です。
みなさんハイキューという漫画(アニメ)はご存知でしょうか。
高校バレーボールを題材にしたスポーツ青春漫画なのですが、ところどころでめっちゃ染みるセリフがあったりして、高校生ではないおじさんでも、バレーにそんなに詳しくない人でも楽しむことができるので、是非読んでみてください。(自分は最近アニメで見ています)



さて本日は、レコメンデーションの文献をいくつかサーベイした中から、TensorFlowを用いた行列分解モデルについてご紹介できればと思います。
はじめに
Matrix Factorizationはその名前の通り、行列分解を行うものです。
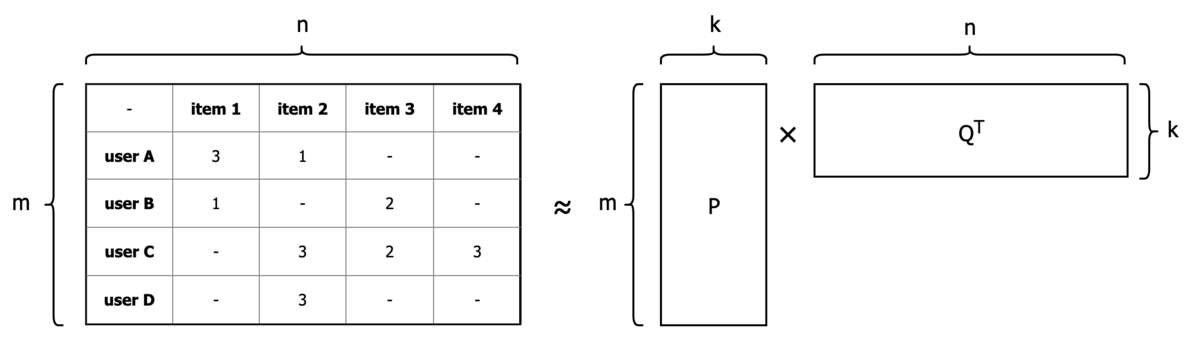
レコメンデーションシステムの文脈では、Rating行列をuserの特徴量行列(P)とitemの特徴量行列(Q)に分解する手法として知られています。
例えば、m人のユーザーとn個のアイテムを考えたときに、m > k > 0であるk次元に次元削減して変換することを目的とします。
これは、評価値を表すRating行列(R)を、ユーザー要素を表すk × mの行列(P)と、アイテム要素を表すk × nの行列(Q)に近似していることになります。
図にすると下記のようなイメージ
また、今回解説する実装はGithubにもあげております。
今回実装する行列分解モデルについて
こちらの論文(MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS )などを参考に、上図の行列分解モデルをベースとしてユーザーとアイテムそれぞれのbiasを考慮したものを、TensorFlowを用いて実装してみます。
ユーザー行列(上図P)とアイテム行列(上図Q)および、ユーザー・アイテムそれぞれのbiasを表現するために、ニューラルネットワークのLayterの1つであるEmbedding Layer*1を用いて実装していきます。
Embedding Layerは、有名どころだと単語の埋め込み表現などを計算するときにも用いられたりするものです。
お気持ちとしては、下記式でユーザーの嗜好がスコアリングできると仮定して学習させています。
:ユーザiによるアイテムjに対する評価値
:ユーザiによる評価値のバイアス。このユーザがつける評価値が全体的に高いか低いかを表す。
:アイテムjに対する評価値のバイアス。このアイテムに対する評価値が全体的に高いか低いかを表す。
:ユーザiの特徴ベクトル。
:アイテムjの特徴ベクトル。
:ユーザiとアイテムjの特徴ベクトルの内積。
また、今回モデリングするネットワークは下記のようなものになります。
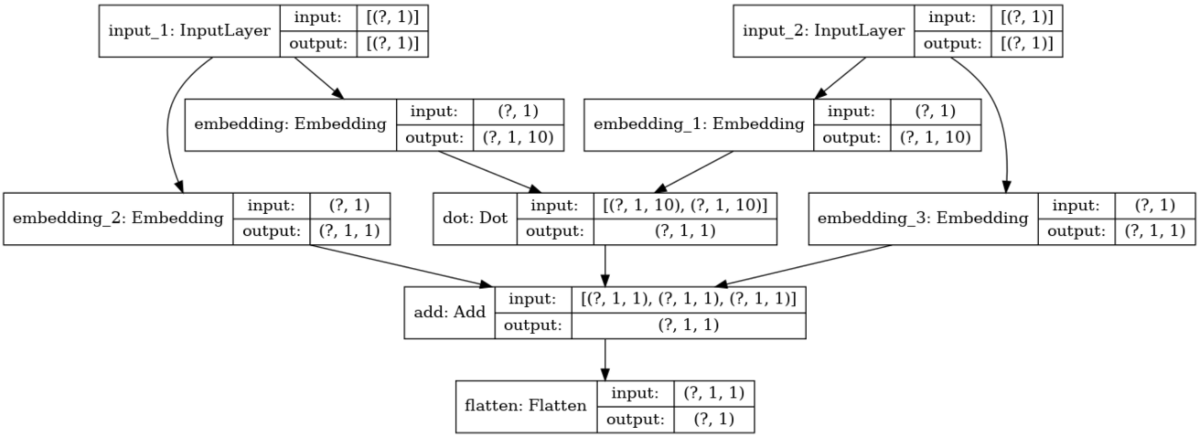
学習後のEmbedding Layerには、ユーザー・アイテムそれぞれの分散表現が格納されているイメージです。
(上図のembedding, embedding_1の部分)
本ポストの後半では、この分散表現を用いたレコメンデーションについても触れています。
なぜTensorFlow(深層学習フレームワーク)を使う必要があるのか
行列分解は、numpy*2やsklearnのNMF*3などを用いれば比較的容易に実装することができます。
しかし、使用できる最適化アルゴリズムやバイアス項の制限もあり、少し使いづらい部分もあります。
そこでTensorFlowなどの深層学習フレームワークを用いることで、好きな最適化アルゴリズム*4やバイアス項を比較的簡単に実装することができます。
また、ニューラルネットワークの構造に落とし込むことができれば、後からよりDeepなモデルにしたりなど、アーキテクチャを容易に変更することも可能になり、PDCAのスピードも速くなるというメリットがあるのかなと思います。
実装
今回使用するデータは、お馴染みのmovie lensデータセットです。
MovieLens 25M Dataset のデータセットをダウンロードし、そこからいくつかデータをサンプリングして実装していきます。
データのサンプリングとindexの付与
今回は実験のため、出現回数の多いデータのみをサンプリングします。
また、TensorFlowのEmbeddingを利用できるようにするために、前処理としてuserとmovieそれぞれに0〜のindex情報を付与します。
import pandas as pd from collections import Counter import tensorflow as tf from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt import seaborn as sns from tqdm.notebook import tqdm # データの読み込み DATA_DIR = './data/ml-25m/' df = pd.read_csv(DATA_DIR + 'ratings.csv') # 出現回数の多いuserとmovieに絞る n = 10000 # userはTOP:10000 m = 2000 # movieはTOP:2000 user_ids_count = Counter(df.userId) movie_ids_count = Counter(df.movieId) user_ids = [u for u, c in user_ids_count.most_common(n)] movie_ids = [m for m, c in movie_ids_count.most_common(m)] df_small = df[df.userId.isin(user_ids) & df.movieId.isin(movie_ids)] # indexを付与する user_id_map = {} for i, u_id in enumerate(user_ids): user_id_map[u_id] = i movie_id_map = {} for i, m_id in enumerate(movie_ids): movie_id_map[m_id] = i df_small.loc[:, 'user_idx'] = df_small.progress_apply(lambda row: user_id_map[row.userId], axis=1) df_small.loc[:, 'movie_idx'] = df_small.progress_apply(lambda row: movie_id_map[row.movieId], axis=1) # 保存しておく df_small.to_csv(DATA_DIR + 'edited_ratings.csv', index=False)
今回使用したrating.csvは、処理前と処理後で下記のようなデータになっています。
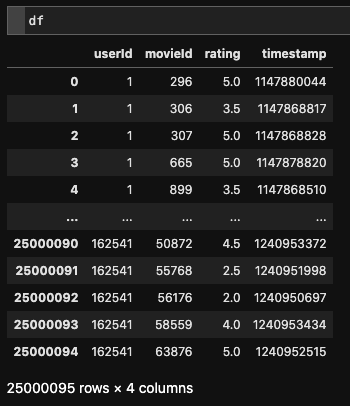
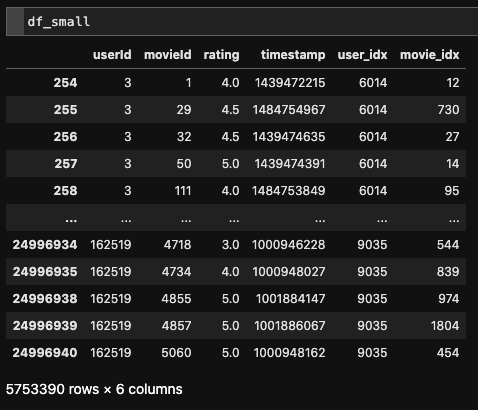
ここまでで学習に使用できるデータができました。
TensorFlow.kerasでの学習
上記でデータ生成ができたので、TensorFlowで学習させていきます。
冒頭でも少し紹介しましたが、Embbeding Layerではuserとmovieそれぞれの埋め込みベクトルが計算されます。
そこでEmbbeding Layerの形状を指定するために、userとmovieのユニーク数を取得しそれをモデルに渡します。
ちなみに、今回は埋め込みベクトルの次元数(冒頭の図でいうところのk)は10にしています。
user_num = df_small.user_idx.max() + 1 # number of users movie_num = df_small.movie_idx.max() + 1 # number of movies print(user_num, movie_num) # -> 10000 2000 # train, testの分割 train, test = train_test_split(df_small, test_size=0.3, shuffle=True, random_state=42) print(train.shape, test.shape) # ->(4027373, 6) (1726017, 6) def create_model(user_num: int, movie_num: int, k: int = 10) -> tf.keras.models.Model: """kerasでMatrix Factorizationのモデルを構築する Args: user_num (int): ユニークユーザー数 movie_num (int): ユニーク映画数 k (int): 埋め込み層の次元数 Returns: tf.keras.models.Model: モデルインスタンス """ u = tf.keras.layers.Input(shape=(1,)) m = tf.keras.layers.Input(shape=(1,)) u_embedding = tf.keras.layers.Embedding(user_num, k)(u) m_embedding = tf.keras.layers.Embedding(movie_num, k)(m) u_bias = tf.keras.layers.Embedding(user_num, 1)(u) m_bias = tf.keras.layers.Embedding(movie_num, 1)(m) x = tf.keras.layers.Dot(axes=2)([u_embedding, m_embedding]) x = tf.keras.layers.Add()([x, u_bias, m_bias]) x = tf.keras.layers.Flatten()(x) model = tf.keras.models.Model(inputs=[u, m], outputs=x) opt = tf.keras.optimizers.SGD(learning_rate=0.1, momentum=0.9) model.compile( loss=tf.keras.losses.MeanSquaredError(), optimizer=opt, metrics=[tf.keras.metrics.RootMeanSquaredError()], ) return model # モデルの定義 model = create_model(user_num, movie_num) tf.keras.utils.plot_model(model, show_shapes=True) # ネットワーク構造をプロットできる # callback関数を定義 early_stopping = tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=5, restore_best_weights=True, verbose=0, ) checkpoint = tf.keras.callbacks.ModelCheckpoint( 'keras.h5', monitor='val_loss', save_best_only=True, save_weights_only=True, mode='min', verbose=0, ) # 学習 result = model.fit( x=[train.user_idx.values, train.movie_idx.values], y=train.rating.values, epochs=200, batch_size=1024, validation_data=( [test.user_idx.values, test.movie_idx.values], test.rating.values ), callbacks=[early_stopping, checkpoint], verbose=1, ) # -> Epoch 1/200 # -> 3933/3933 [==============================] - 9s 2ms/step - loss: 2.0342 - root_mean_squared_error: 1.4263 - val_loss: 0.7522 - val_root_mean_squared_error: 0.8673 # -> Epoch 2/200 # -> 3933/3933 [==============================] - 10s 3ms/step - loss: 0.7092 - root_mean_squared_error: 0.8421 - val_loss: 0.6880 - val_root_mean_squared_error: 0.8295 # -> ... # -> Epoch 124/200 # -> 3933/3933 [==============================] - 9s 2ms/step - loss: 0.5016 - root_mean_squared_error: 0.7083 - val_loss: 0.5360 - val_root_mean_squared_error: 0.7321
暫くすると学習が終わります。
学習結果
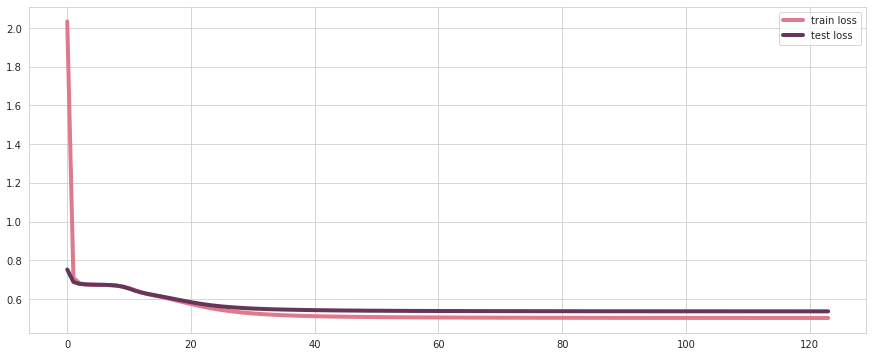
学習曲線をプロットしてみます。
epoch=60くらいでサチっているように見えますが、悪くはなさそうです。
(実際には、val_loss: 0.5360でearly_stoppingがかかっています)
sns.set_context({"lines.linewidth": 4})
plt.subplots(figsize=(15, 6))
sns.lineplot(data=result.history['loss'], label="train loss", color=colors_nude[0])
sns.lineplot(data=result.history['val_loss'], label="test loss", color=colors_nude[1])
plt.legend()
plt.show()
レコメンドに活かす方法
今回は行列分解がレコメンデーションにどのように活用できそうか、という投稿なので、上記の結果・モデルをどのようにレコメンデーションに活かすことができるかについて考察してみます。
結果を分かりやすくするために、ひとまずmovieのタイトル情報をtrain, testにマージしておきます。
movie = pd.read_csv(DATA_DIR + 'movies.csv') # train, testとマージする train = pd.merge(train, movie, how='left', on='movieId') test = pd.merge(test, movie, how='left', on='movieId')
ちなみに、movie.csvは以下のようなデータになっています。
推論結果を利用するパターン
今回は、user_idxとmovie_idxが分かればuserがどのmovieに興味があるのかを推論することができます。
したがって、単純に予測した値の高いmovieをレコメンドする、という方法が考えられます。
# テストデータに対して推論 test.loc[:, 'pred_rating'] = model.predict([test.user_idx.values, test.movie_idx.values], verbose=1)
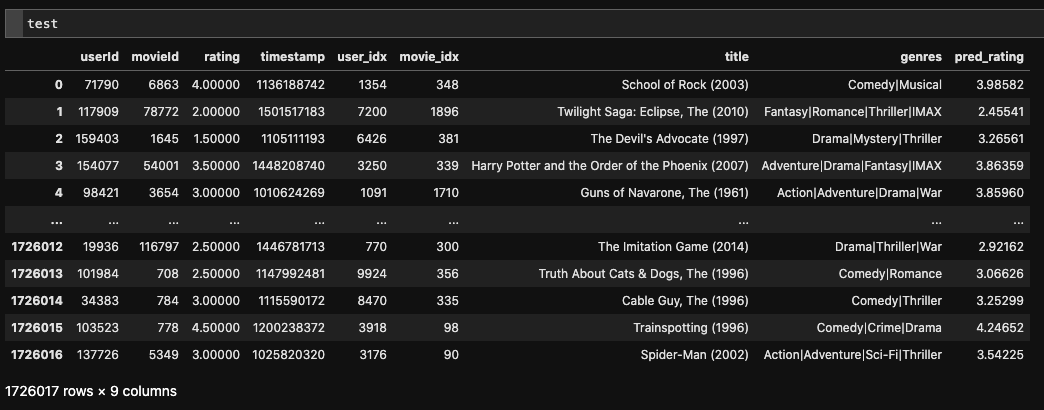
推論結果が付与され、testデータは以下のようになりました。
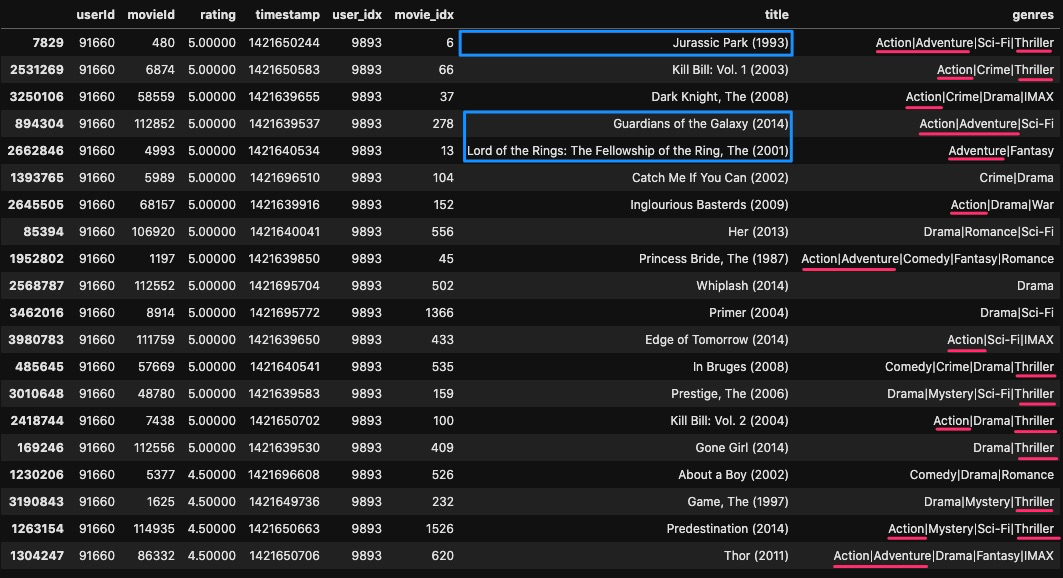
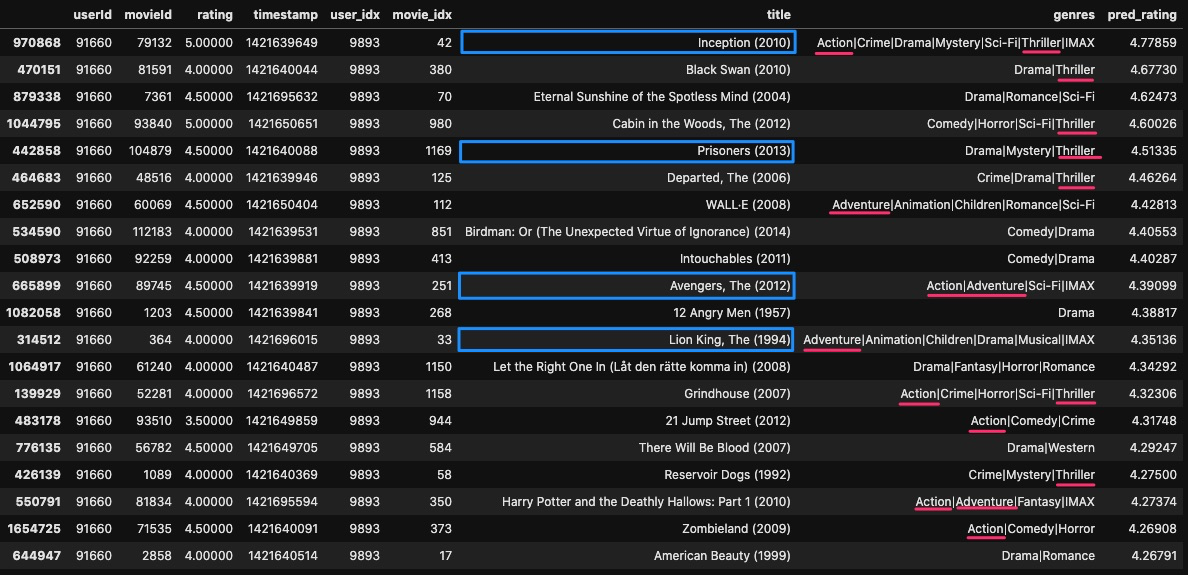
例として、user_id = 91660のユーザーに対して、どのようなmovieがレコメンドされるのかを見てみましょう。
# 実験 user_id = 91660 # trainで見ているmovieでratingの高いものTOP:20 train.query('userId == @user_id').sort_values('rating', ascending=False).head(20)
学習データを見てみると、ジュラシック・パーク, ガーディアンズ・オブ・ギャラクシー, ロード・オブ・ザ・リングなどの映画に高いratingをつけています。
また、ジャンルをみると、Action, Drama, Thriller などの単語が頻出しています。
このことから、このユーザーは恋愛映画のような穏やかな作品より、バトルものなどの作品が好みだということが言えそうです。
では、推論結果(testデータ)ではどうでしょうか。
予測されたratingが高いものを見てみると、インセプション, プリズナーズ, アベンジャーズ など、ハラハラするバトルものなどがレコメンドされそうです。
また、ジャンルを見ても定性的ではありますが比較的好みを当てていそうではあります。
# レコメンドされるmovie TOP:20 test.query('userId == @user_id').sort_values('pred_rating', ascending=False).head(20)
Embbeding Layerのweightを利用するパターン
もう1つレコメンドに使えるものとして、Embbeding Layerの埋め込みベクトル(重み)が挙げられるかな、と思います。
Embbeding Layerには各userと各movieの分散表現が計算されているので、例えばコサイン類似度などを用いて類似映画を計算できそうです。
ここではジュラシック・パーク、トイ・ストーリーと似ている / 似ていない映画をそれぞれ計算してみます。
まずは諸々の準備をします。
# utils _df = df_small[['movieId', 'movie_idx']].drop_duplicates() # 重複を排除したデータ def sim_movie(movie_df, movie_idx, asc=False, N=10): """類似映画IDTOP:N件を返却する関数 """ sim_movie_df = cos_df.iloc[:, movie_idx:movie_idx+1].sort_values(movie_idx, ascending=asc)[:N].reset_index().rename(columns={movie_idx: 'cos_sim', 'index': 'movie_idx'}) sim_movie_df = pd.merge(sim_movie_df, _df, how='left', on='movie_idx') return pd.merge(sim_movie_df, movie_df, how='left', on='movieId') def cos_sim_matrix(matrix): """コサイン類似度を計算する関数 """ d = matrix @ matrix.T # item-vector 同士の内積を要素とする行列 norm = (matrix * matrix).sum(axis=1, keepdims=True) ** .5 return d / norm / norm.T # 全movieのコサイン類似度行列を計算 cos_df = cos_sim_matrix(movie_emb_layer.get_weights()[0]) cos_df = pd.DataFrame(cos_df)
ジュラシック・パークと似ている / 似ていない映画
まずはジュラシック・パークを例に見てみます。
# ジュラシック・パークのmovie_idxを取得 movie_id = 480 # ジュラシック・パーク movie_idx = train.query('movieId == @movie_id')['movie_idx'].unique()[0] # 類似度の高い順 sim_df = sim_movie(movie, movie_idx, False, 20)
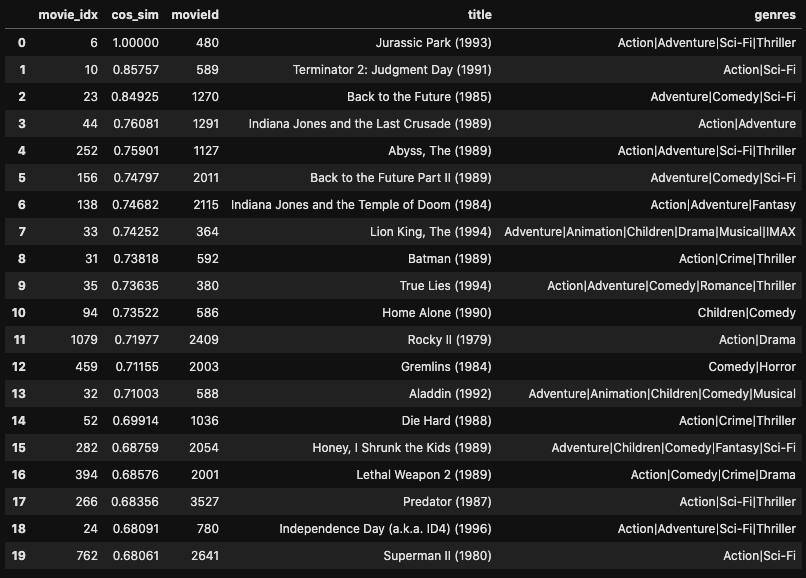
比較的良さそうな結果が出てきました。
類似度が低いmovieも見てみます。
# 類似度が低い順 sim_df = sim_movie(movie, movie_idx, True, 20)
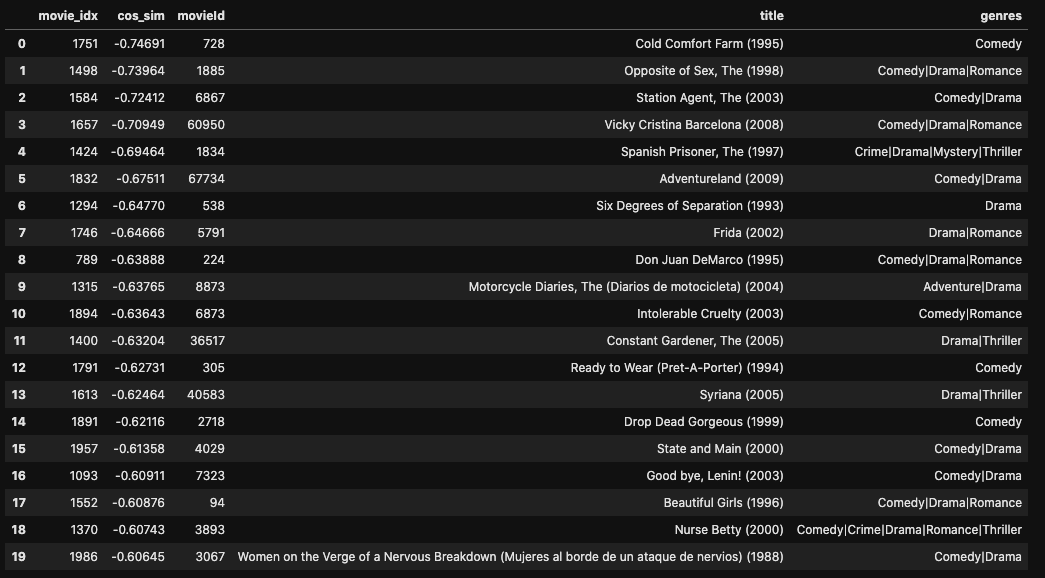
こちらはコメディーもののmovieが多く、定性的ではありますがジュラシック・パークとは性質の異なるmovieが計算されているように感じます。
トイ・ストーリーと似ている / 似ていない映画
トイ・ストーリーでもチェックしてみます。
# トイ・ストーリーのmovie_idxを取得 movie_id = 1 # トイ・ストーリー movie_idx = train.query('movieId == @movie_id')['movie_idx'].unique()[0] # 類似度の高い順 sim_df = sim_movie(movie, movie_idx, False, 20)
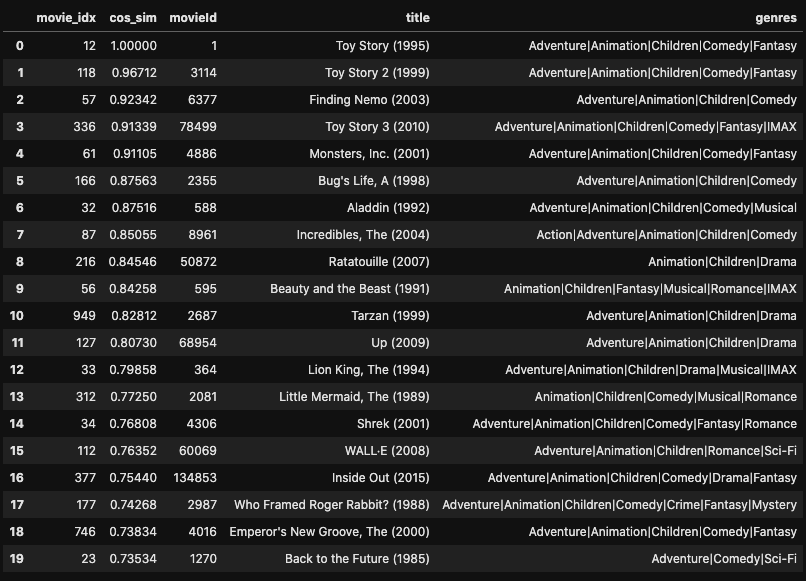
トイ・ストーリー2, トイ・ストーリー3, といったシリーズや、ディズニー作品が上位に多く出てきているので、こちらも比較的良い結果になったと言えそうです。
類似度が低いmovieも見ておきます。
# 類似度が低い順 sim_df = sim_movie(movie, movie_idx, True, 20)
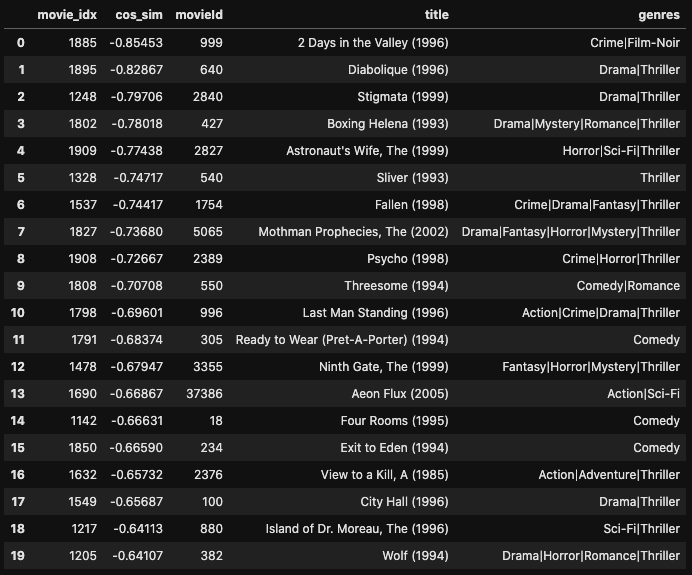
こちらはスリラーやコメディー系のmovieが多くあり、ジュラシック・パーク同様に良い結果が出ていると言えそうです。
最後に
本日は、レコメンデーションの1つの手法であるMatrix Factorization(行列分解)について、tf.kerasを用いて実装してみました。
レコメンデーションは奥が深く、まだまだ学習すべきことは多いですが、今関わっているプロダクトを通じて、ユーザーに価値を届けられるようにチャレンジし続けたいと思います。