みなさんこんにちは。たかぱい(@takapy0210)です。
本エントリでは、(今更ながら)Luigiを使ってみて感じたメリットをつらつら書いています。
最後にはTitanicのコードを使って実際の機械学習パイプラインを構築してみた例も載せているので、よければ参考にしてみてください。
本ブログで記載しているコードはGithubにもあげています。
Luigiとは
Luigiとは、SpotifyがOSSとして開発しているpythonのバッチ処理フレームワークです。
データ処理をTaskという単位で定義していき、依存関係の記述やワークフローの可視化などを行うことができます。
以下、READMEから転記
Luigi is a Python (3.6, 3.7, 3.8, 3.9 tested) package that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, handling failures, command line integration, and much more.
基本的に各Taskには以下3つのメソッドを実装する必要があります。
- requires:自身の処理に依存する上位Taskを記述
- output:自身の出力ファイルを記述
- run:自身の処理内容を記述
処理のイメージとしては
- outputメソッドがTrueを返す(そのTaskが既に実行済み)場合は、runメソッドを実行しない。
- outputメソッドがFalseを返す(そのTaskが実行されていない)場合は、runメソッドを実行して、出力を作成する。
→この機構により、既に実行済みのTaskを再実行しなくて済むので、実験回数を向上させることができる - requiresメソッドで依存TaskのoutputがFalseを返す(依存Taskが実行されていない)場合は、先に依存Taskのrunを実行する。
という流れです。
詳細は後述しますが、記述イメージはざっくり以下のようになります。
(このタスクは依存する上位タスクが存在しないので、requiresは定義していません。)
class LoadDataset(luigi.Task): """データセットをロードするクラス""" def output(self): # return luigi.LocalTarget("data/titanic.csv") # csvで出力する場合 return luigi.LocalTarget("data/titanic.pkl", format=luigi.format.Nop) def run(self): # titanicデータの読み込み df = datasets.fetch_openml("titanic", version=1, as_frame=True, return_X_y=False).frame logger.info(f'Data shape: {df.shape}') # pklで出力する with self.output().open('w') as f: f.write(pickle.dumps(df, protocol=pickle.HIGHEST_PROTOCOL))
ドキュメントはこちらです。
Luigiを使うメリット
実際に使ってみて3つほどメリットを感じました。
- コードのメンテナンス性向上
- 再現性の向上
- 実験回数の向上
コードのメンテナンス性向上
フレームワークに則ることでコーディングがある程度強制されるので、誰が書いても同じようなコードになります。
これはコードの保守性の観点から考えても非常に良いことだと思いました。
再現性の向上
notebookなどで処理を書いていると、セルの実行順によって処理結果が異なって発狂したことがある人も多いと思います。
この辺りはスクリプト化することである程度回避できる + Luigiフレームワークに則ることでより一層堅牢になると感じました。
実験回数の向上
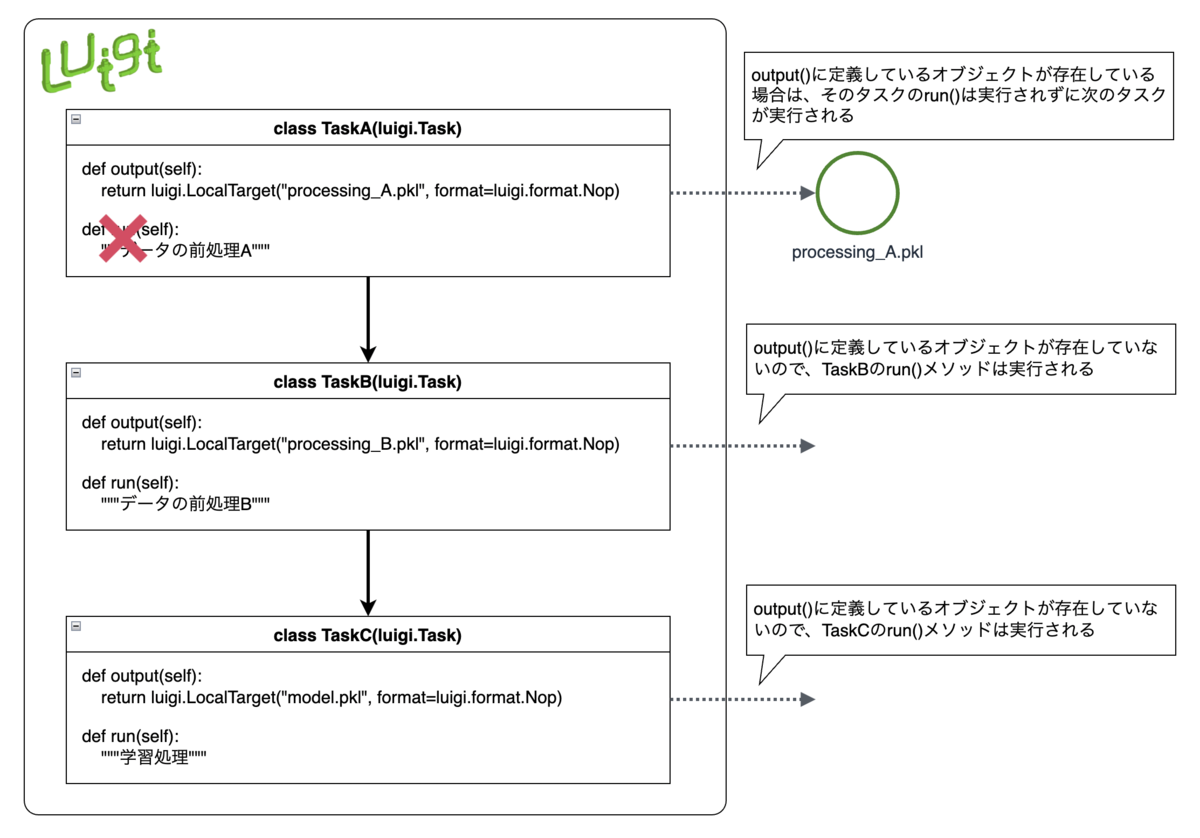
言葉で説明してもわかりづらいと思うので、図を書いてみました。
下図は、TaskA(データの前処理)→TaskB(データの前処理)→TaskC(モデルの学習処理)とうパイプラインを表したものです。
この場合processing_A.pklというデータが存在しているので(TaskAは過去に実行済みと判断され)TaskAの実行はスキップされ、TaskB→TaskCという順に処理されます。
このようにoutput()に定義したオブジェクトの存在有無により、自動的にTaskを実行すべきかを判断してくれます。
例えば、TaskAの処理が数十分〜数時間かかるような場合、パイプラインを実行するたびにTaskAから実行されるのは本意ではないと思います。(もちろん、TaskAの処理を変更した場合は再実行してほしいと思うので、その場合は該当のオブジェクトを削除して再実行する必要があります)
そういった場合において、不要なTaskは自動的にスキップしてくれるので、いろいろ実験する際には役立ちそうです。
使用する上でのTips
実際に使用する際に使えそうなTipsをいくつか紹介します
requiresはデコレータを用いる
冒頭で紹介したrequires()メソッドですが以下で紹介するようにデコレートすることができます。
例えば以下のような処理を
import luigi class TaskA(luigi.Task): def run(self): hoge... class TaskB(luigi.Task): def requires(self): return TaskA() def run(self): hoge...
こんな感じで記述できます。ちょっとスッキリしますね!
import luigi from luigi.util import requires class TaskA(luigi.Task): def run(self): hoge... @requires(TaskA) class TaskB(luigi.Task): def run(self): hoge...
任意のフォーマットでログ出力する
冒頭で紹介したリポジトリにあるように、実行時に luigi.configuration.LuigiConfigParser.add_config_path('./luigi.cfg') という形で設定ファイルを読み込んでいます。
この中にloggerのconfigファイルを指定することで、任意のフォーマットでログ出力ができます。
サンプルとして、リポジトリに上がっている例を載せておきます。
luigi.cfg
[core] # 不要なログを出力しないための設定 log_level=INFO logging_conf_file=logging.conf [retcode] already_running=10 missing_data=20 not_run=25 task_failed=30 scheduling_error=35 unhandled_exception=40
エラー通知の設定はドキュメントにもサンプルが載っています。
logging.conf
[loggers] keys=root [handlers] keys=streamHandler [logger_root] level=INFO handlers=streamHandler [formatters] keys=simpleFormatter [handler_streamHandler] class=logging.StreamHandler level=INFO formatter=simpleFormatter [formatter_simpleFormatter] format=[%(asctime)s] [%(levelname)5s] %(message)s datefmt=%Y-%m-%d %H:%M:%S
ブラウザからパイプラインの実行結果の可視化をしてみる
実行時のコマンドで、local_schedulerを使わないようにすると、ブラウザからhttp://localhost:8082/にアクセスすることで、パイプラインの実行結果を可視化することができます。
if __name__ == '__main__': # 設定ファイルの読み込み luigi.configuration.LuigiConfigParser.add_config_path('./luigi.cfg') # 実行 # luigi.build([MyInvokerTask()], local_scheduler=True) luigi.build([MyInvokerTask()], local_scheduler=False) # ブラウザからチェックしたい場合はこちら
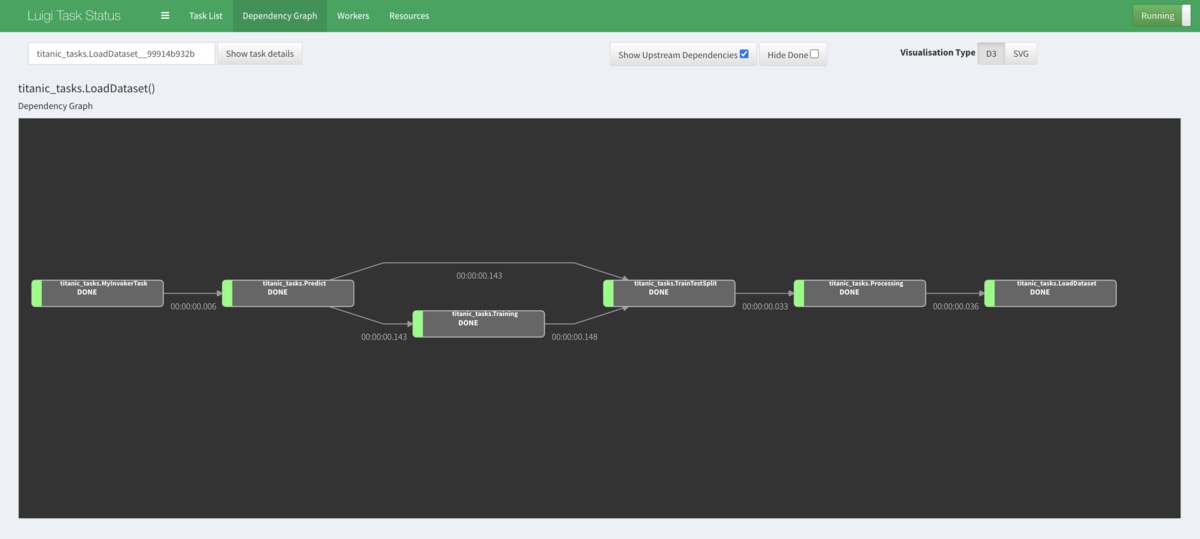
今回の処理だと一瞬で終了してしまうので、実行中の動作は見れませんが、興味がある人は少し重い処理を実行してみると、パイプラインのステータスが変わっていく様子が見れると思うので、試してみてはいかがでしょうか。
実際のコンペデータをLuigiフレームワークに載せてみる
有名なTitanicデータを用いてデータの読み込み・前処理〜学習までのコードをLuigiのフレームワークに則って記述してみます。
コメントしているように、csvでの入出力もできたり、複数ファイルの入出力にも対応しています。(csvは型が崩れる可能性があるので非推奨ではありそうです)
import pickle import warnings import logging import pandas as pd import luigi from luigi.util import requires from sklearn import datasets from sklearn.preprocessing import OneHotEncoder from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report, accuracy_score warnings.filterwarnings("ignore") logger = logging.getLogger() class LoadDataset(luigi.Task): """データセットをロードするクラス""" task_namespace = 'titanic_tasks' def output(self): # return luigi.LocalTarget("data/titanic.csv") # csvで出力する場合 return luigi.LocalTarget("data/titanic.pkl", format=luigi.format.Nop) def run(self): # titanicデータの読み込み df = datasets.fetch_openml("titanic", version=1, as_frame=True, return_X_y=False).frame logger.info(f'Data shape: {df.shape}') # pklで出力する with self.output().open('w') as f: f.write(pickle.dumps(df, protocol=pickle.HIGHEST_PROTOCOL)) # csvで出力したい場合は普通にpandasで出力する # 型が崩れる可能性があるので非推奨ではある # df.to_csv("data/titanic.csv", index=False) @requires(LoadDataset) class Processing(luigi.Task): """データの加工を行う""" task_namespace = 'titanic_tasks' def output(self): # return luigi.LocalTarget("data/processing_titanic.csv") # csvで出力する場合 return luigi.LocalTarget("data/processing_titanic.pkl", format=luigi.format.Nop) def run(self): # データの読み込み with self.input().open() as f: # df = pd.read_csv(f) # pandasで読み込むパターン df = pickle.load(f) # pickleで読み込むパターン logger.info(f'Before Data shape: {df.shape}') # 欠損値処理 df.loc[:, 'age'] = df['age'].fillna(df['age'].mean()) df.loc[:, 'fare'] = df['fare'].fillna(df['fare'].mean()) # カテゴリエンコード categorical_cols = ["pclass", "sex", "embarked"] df = self.sklearn_oh_encoder(df=df, cols=categorical_cols, drop_col=True) logger.info(f'After Data shape: {df.shape}') # 学習に使用するカラムのみを出力 use_cols = [ 'survived', 'age', 'sibsp', 'parch', 'fare', 'pclass_1.0', 'pclass_2.0', 'pclass_3.0', 'sex_female', 'sex_male', 'embarked_C', 'embarked_Q', 'embarked_S', 'embarked_nan' ] df = df[use_cols] # 保存 with self.output().open('w') as f: f.write(pickle.dumps(df, protocol=pickle.HIGHEST_PROTOCOL)) def sklearn_oh_encoder(self, df, cols, drop_col=False): """カテゴリ変換 sklearnのOneHotEncoderでEncodingを行う Args: df: カテゴリ変換する対象のデータフレーム cols (list of str): カテゴリ変換する対象のカラムリスト drop_col (bool): エンコード対象のカラムを削除するか否か Returns: pd.Dataframe: dfにカテゴリ変換したカラムを追加したデータフレーム """ output_df = df.copy() for col in cols: ohe = OneHotEncoder(sparse=False, handle_unknown='ignore') ohe_df = pd.DataFrame((ohe.fit_transform(output_df[[col]])), columns=ohe.categories_[0]) ohe_df = ohe_df.add_prefix(f'{col}_') # 元のDFに結合 output_df = pd.concat([output_df, ohe_df], axis=1) if drop_col: output_df = output_df.drop(col, axis=1) return output_df @requires(Processing) class TrainTestSplit(luigi.Task): """データを学習データと検証データに分割する""" task_namespace = 'titanic_tasks' def output(self): return [luigi.LocalTarget("data/processing_titanic_train.pkl", format=luigi.format.Nop), luigi.LocalTarget("data/processing_titanic_test.pkl", format=luigi.format.Nop)] def run(self): # データの読み込み with self.input().open() as f: df = pickle.load(f) # pickleで読み込むパターン train, test = train_test_split(df, test_size=0.3, shuffle=True, stratify=df['survived'], random_state=42) logger.info(f'Train shape: {train.shape}') logger.info(f'Test shape: {test.shape}') with self.output()[0].open('w') as f: f.write(pickle.dumps(train, protocol=pickle.HIGHEST_PROTOCOL)) with self.output()[1].open('w') as f: f.write(pickle.dumps(test, protocol=pickle.HIGHEST_PROTOCOL)) @requires(TrainTestSplit) class Training(luigi.Task): """学習""" task_namespace = 'titanic_tasks' def output(self): return luigi.LocalTarget("model/random_forest.model", format=luigi.format.Nop) def run(self): # データの読み込み with self.input()[0].open() as f: train = pickle.load(f) logger.info(f'Train shape: {train.shape}') target_col = 'survived' X_train = train.drop(target_col, axis=1) y_train = train[target_col] model = RandomForestClassifier(random_state=1) model.fit(X_train, y_train) # 保存 with self.output().open('w') as f: f.write(pickle.dumps(model, protocol=pickle.HIGHEST_PROTOCOL)) @requires(TrainTestSplit, Training) class Predict(luigi.Task): """推論""" task_namespace = 'titanic_tasks' def output(self): return luigi.LocalTarget("data/predict_data.csv") def run(self): # データの読み込み with self.input()[0][1].open() as f: valid = pickle.load(f) # モデルの読み込み with self.input()[1].open() as f: model = pickle.load(f) logger.info(f'Valid data shape: {valid.shape}') target_col = 'survived' X_valid = valid.drop(target_col, axis=1) y_valid = valid[target_col] # 予測 y_pred = model.predict(X_valid) logger.info(f'Accuracy Score: {accuracy_score(y_valid, y_pred)}') logger.info('\n' + classification_report(y_valid, y_pred)) # # 保存 valid.loc[:, 'y_pred'] = y_pred valid.to_csv('data/predict_data.csv', index=False) @requires(Predict) class MyInvokerTask(luigi.WrapperTask): task_namespace = 'titanic_tasks' pass if __name__ == '__main__': # 設定ファイルの読み込み luigi.configuration.LuigiConfigParser.add_config_path('./luigi.cfg') # 実行 luigi.build([MyInvokerTask()], local_scheduler=True) # luigi.build([MyInvokerTask()], local_scheduler=False) # ブラウザからチェックしたい場合はこちら
最後に
Luigiフレームワークに則ることで、いろいろなメリットを享受することができそうでした。
個人的には実験回数の向上が一番のメリットかなぁとも感じたので、コンペや実務で積極的に使っていこうと思いました。