
こんにちは。takapy(@takapy0210)です。
本エントリは下記イベントでLTした内容の元に、補足事項やコードスニペットなどをまとめたものになります。
ちなみに今回LTしようと思ったきっかけは以下のような出来事からだったので、みなさんのTipsなども教えていただけると嬉しいです!
情報出回ってる感あるけど、colab pro × vscode ssh のオレオレ運用方法を晒すことにより、もっと良い方法のフィードバックもらえるのではドリブンでLTするのはありなのかもしれない・・・?
— takapy | たかぱい (@takapy0210) 2021年8月1日
LT資料
こちらからご覧いただけます。
https://speakerdeck.com/takapy/googlecolabtovscodewoyong-itafen-xi-huan-jing-yun-yong-tips
当日みなさんから頂いたコメント
反応いただいた方ありがとうございました!
当日Twitterで頂いたコメントをいくつかこちらにまとめておこうと思います。
使用する場合はしんちろさんのおっしゃるとおり、自己責任でお願いできればと思います🙏#分析コンペLT
— しんちろ (@sinchir0) 2021年8月17日
ngrokはセキュリティリスクあるので自己責任でhttps://t.co/4xWvIV3oqF
たしかにちょっと不安な部分ではありますね...推論スクリプトをデータセットに入れているとのことですが、最終サブでもそうしてますか?
— oɹɐʇuǝʞ (@cfiken) 2021年8月17日
自分も同じようなことをしてるのですが、external dataset のルールが曖昧なせいで最終サブだけ Kaggle Notebook にベタ書きしてるんですよね。。#分析コンペLT
CommonLitコンペ*1は大丈夫でした(が、安全策をとるならnotebookにちゃんと移行した方がよいかもしれません)
以下のような事例も共有いただきました。ありがとうございます!
ノウハウというほどではないけど、notebookから.py呼ぶ方式でcolab使った時は、keepsakeで実験管理したら.py一式を自動でgcsに保存&いつでもcheckoutでロールバックできて体験が良かった #分析コンペLT
— Nomi (@nyanp) 2021年8月17日
踏み台をawsやgcpに立てて、colabから踏み台にsshアクセス(ポートフォワードあり)→ローカルからsshで踏み台にアクセス(ポートフォワードあり)→別sshでフォワードされたポートにアクセス
— K-NKSM (@KNKSM5) 2021年8月17日
ってやってる#分析コンペLT
colab proにcolab-sshで接続してる
— 名無し。 (@496_nnc) 2021年8月17日
データの解答とか接続とか諸々設定書いたnotebook用意しておいてrun-allして接続してる。毎回コンテナ変わるからgitのconfigとかパッケージのインストールとかMakefileにまとめておいて何回かコマンド叩くだけで環境できるようにしてる
#分析コンペLT
全てのツイートは以下から見れます↓
ここからは、スライドの補足やサンプルコードの紹介をしていきます。
環境構築手順
資料内にある環境構築手順について、コードを交えながら補足していきます。
LT資料の冒頭にも記載していますが、ここで紹介する方法はGoogle側が推奨している使用方法ではないので、あらかじめご了承ください。(急に使えなくなったりする可能性もあると思っていますので、使用する際は自己責任でお願いします)
ngrokアカウント作成と認証キーの取得
ngrokというサービスに無料アカウントを作成します。
このサービスを使用することで、ローカルIPアドレスしか持たないホストに、外部のネットワークからアクセスすることができるようになったりします。 また、SSHのトンネルとしても使用することができるサービスです。
Colabを使用する際にはGoogleアカウントが必要となりますので、Googleアカウントで紐づけるのが無難かと思います。
アカウントが作成できたら、ログインし、Your Authtoken の値をコピーしておきます。(次に説明するsshサーバーを起動する部分で使用します)

ColabにGoogleドライブを接続、ngrok、sshサーバー起動
Colabを起動し、GPU接続ON、Googleドライブ接続を行ったあと、下記手順に沿ってnotebook上でコードを実行していきます。
このnotebookは一度作ってしまえば、2回目以降は同じnotebookを実行すればOKです。
まずはGPUがうまく接続できているかチェックしておきます(これはやらなくてもOKです)
!cat /etc/lsb-release !nvcc -V !nvidia-smi
# 出力結果例 >> DISTRIB_ID=Ubuntu DISTRIB_RELEASE=18.04 DISTRIB_CODENAME=bionic DISTRIB_DESCRIPTION="Ubuntu 18.04.5 LTS" nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2020 NVIDIA Corporation Built on Wed_Jul_22_19:09:09_PDT_2020 Cuda compilation tools, release 11.0, V11.0.221 Build cuda_11.0_bu.TC445_37.28845127_0 Mon Aug 16 13:49:54 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.42.01 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 | | N/A 37C P0 27W / 250W | 0MiB / 16280MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
ngrokのインストール・設定
!apt-get -y update !wget -q -c -nc https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip !unzip -qq -n ngrok-stable-linux-amd64.zip # sshの設定 !apt-get install -qq -o=Dpkg::Use-Pty=0 openssh-server pwgen > /dev/null
sshサーバーの起動
import random, string, urllib.request, json, getpass # Generate root password password = ''.join(random.choice(string.ascii_letters + string.digits) for i in range(20)) # Set root password !echo root:$password | chpasswd !mkdir -p /var/run/sshd !echo "PermitRootLogin yes" >> /etc/ssh/sshd_config !echo "PasswordAuthentication yes" >> /etc/ssh/sshd_config !echo "LD_LIBRARY_PATH=/usr/lib64-nvidia" >> /root/.bashrc !echo "export LD_LIBRARY_PATH" >> /root/.bashrc # Run sshd get_ipython().system_raw('/usr/sbin/sshd -D &') # アクセストークンの設定 # https://dashboard.ngrok.com/auth/your-authtoken authtoken="上記で取得したYour Authtokenの値" # Create tunnel get_ipython().system_raw('./ngrok authtoken $authtoken && ./ngrok tcp 22 &')
Colabサーバーの環境設定
下記設定を行うことで、VSCodeから接続した際にローカル環境と同等の環境を実現することができます。
この例ではzshを使っていますが、ここはお好きなシェル(ローカルで日常的に使っている物が良い)をインストールしてください。
シェルの設定ファイルも、ローカルのものをGoogle Driveにアップロードしておき、それをコピーしておくことで同じ環境を構築できます。
# シンボリックリンクを作成 !ln -sfn /content/drive/MyDrive/workspace /root/workspace # zshのインストール !sudo apt-get install zsh # oh-my-zshのインストール !wget https://github.com/robbyrussell/oh-my-zsh/raw/master/tools/install.sh -O - | zsh || true # zshをデフォルトに設定 !chsh -s /usr/bin/zsh # bashファイルの作成 !echo 'export PATH=/usr/local/cuda/bin:$PATH' >> /root/.bash_profile !echo 'export LD_LIBRARY_PATH=/usr/lib64-nvidia' >> /root/.bash_profile !echo 'export PROMPT_COMMAND="history -a"' >> /root/.bash_profile !echo 'export HISTFILE=/root/.zsh-history' >> /root/.bash_profile !echo 'export PYTHONDONTWRITEBYTECODE=1' >> /root/.bash_profile !echo 'export TF_CPP_MIN_LOG_LEVEL=2' >> /root/.bash_profile # ファイルをgoogle driveからサーバーへコピー !cp /content/drive/MyDrive/workspace/.gitconfig .gitconfig !cp /content/drive/MyDrive/workspace/.zshrc .zshrc
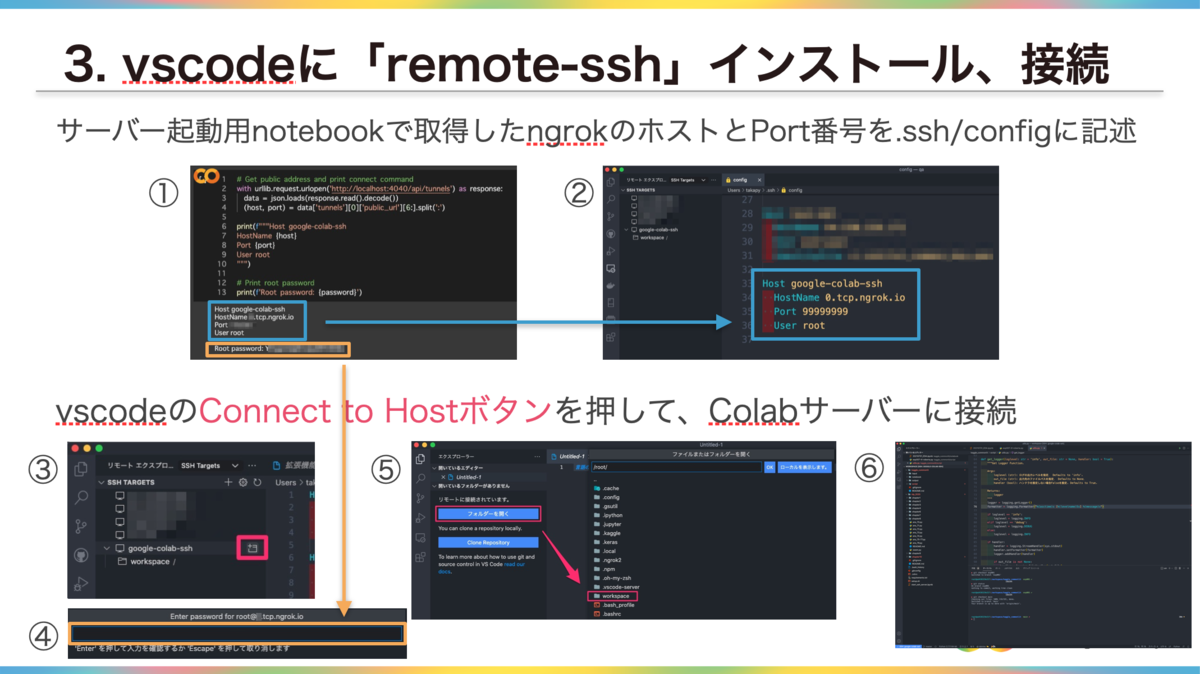
接続情報の取得
最後に、VSCodeからssh接続するために必要な情報を取得します。
Calabの接続が切れてしまうと、このホスト名とポート番号も変わってしまうので、その場合はconfig情報も更新した後、再度VSCodeからssh接続する必要があります。
# Get public address and print connect command with urllib.request.urlopen('http://localhost:4040/api/tunnels') as response: data = json.loads(response.read().decode()) (host, port) = data['tunnels'][0]['public_url'][6:].split(':') print(f"""Host google-colab-ssh HostName {host} Port {port} User root """) # Print root password print(f'Root password: {password}')
# 出力結果例 >> Host google-colab-ssh HostName 0.tcp.ngrok.io Port 9999 User root Root password: HOGEHOGE
以下は実際の接続手順となっています。(LT資料から抜粋)
運用Tips
最後に、ここまでで構築した環境を、より快適に運用するためのTipsをご紹介します。
setup.shスクリプトを作る
VSCodeの拡張機能やpipでインストールしたいpythonのライブラリを1つのスクリプトにまとめておくといろいろ捗ります。
自分はsetup.shという名前でGoogle Driveのworkspaceディレクトリ(ssh接続先ディレクトリ)に保存しています。
#!/bin/bash # pip install python3 -m pip install -r requirements.txt # Visual Studio Code :: Package list pkglist=( ms-python.python tabnine.tabnine-vscode njpwerner.autodocstring oderwat.indent-rainbow ) for i in ${pkglist[@]}; do code --install-extension $i done
requirements.txtの中身は以下のようになっていて、Colabにはプリインストールされていないpythonライブラリを記載しています。
kaggle transformers texthero flake8
このようなスクリプトを用意しておくことで、VSCodeからssh接続した後、
$ bash setup.sh
を実行するだけで、毎回同じ環境を構築することができます。(便利!)
kaggleで使う場合のTips(コードコンペを例に)
学習/推論スクリプトの中に、”スクリプト本体”と”学習済みモデル”をkaggle Datasetにアップロードする処理を仕込んでおきます。
実際にコンペにsubmitする時は、kaggleのnotebook上からアップロードしたスクリプトを実行するだけで推論処理が行われるようになります。(kaggleのnotebookから!python3 exp001.py みたいな形で実行するイメージです)
後述していますが、このスクリプト内部も若干工夫が必要です。
こうすることで以下のようなメリットを享受できると思っています。
- Colabで作ったモデルを都度手動でDatasetsにアップロードしなくて良い
- Colabでモデルは作ったけど、推論専用のnotebookが無いから0から作らなきゃ…という事態を回避できる
- 推論処理のコードもGithubで管理できる
- kaggleのDatasetsをうまく使うことで、「モデル」と「そのモデルを生成したスクリプト」をセットで管理することもできる(このモデル、どのスクリプトで作ったやつだっけ・・・みたいなことが無くなる)
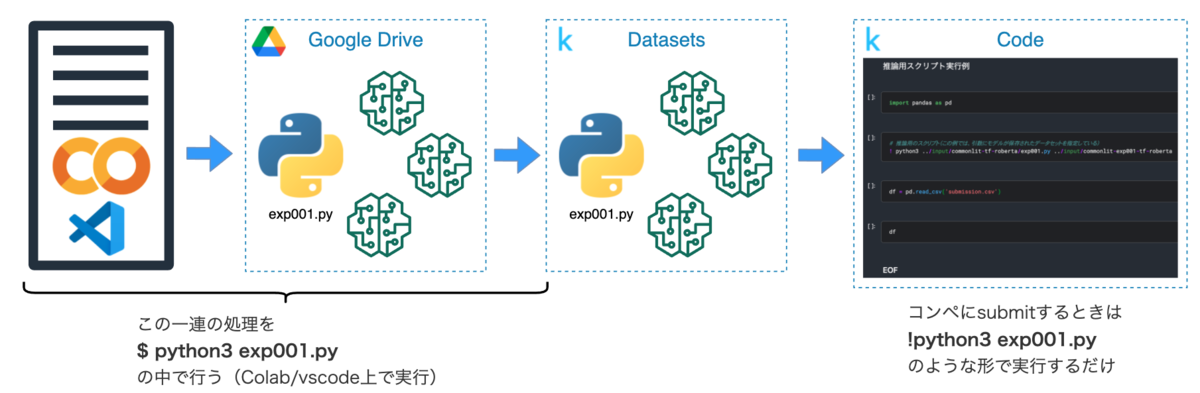
kaggleのデータセットにアップロードする処理は以下のように実装することができます。
下記のサンプルだと、upload_target_dirに対象のGoogle Driveのパスを指定して実行するイメージです。
def upload_kaggle_dataset(user_id, exp_no, upload_target_dir, logger): """kaggleのデータセットにデータをuploadする関数""" from kaggle.api.kaggle_api_extended import KaggleApi _id = f'{user_id}/{exp_no}' dataset_metadata = {} dataset_metadata['id'] = _id dataset_metadata['licenses'] = [{'name': 'CC0-1.0'}] dataset_metadata['title'] = f'{exp_no}' with open(upload_target_dir + '/dataset-metadata.json', 'w') as f: json.dump(dataset_metadata, f, indent=4) api = KaggleApi() api.authenticate() # データセットがない場合 if _id not in [str(d) for d in api.dataset_list(user=user_id, search=exp_no)]: logger.info('No data set, so create a new one.') logger.info(f'URL: https://www.kaggle.com/{_id}') api.dataset_create_new(folder=upload_target_dir, convert_to_csv=False, dir_mode='skip') # データセットがある場合 else: logger.info('Generate a new version because of the data set.') logger.info(f'URL: https://www.kaggle.com/{_id}') api.dataset_create_version(folder=upload_target_dir, version_notes='update', convert_to_csv=False, delete_old_versions=True, dir_mode='skip') return None
学習/推論スクリプト内での工夫ポイント
実際のスクリプト(上図でいうところのexp001.py)の中身ですが、以下のように条件分岐をしておくことで、kaggleのnotebook上では推論処理のみを、その他の環境の時は学習→推論といった一連の処理を行うコードを書くことができます。(場合によってはtestデータ含めて学習し直すケースもあると思いますが)
このようにすることで、学習/推論処理を1つのスクリプトで管理できます。
import os if __name__ == '__main__': # 学習 if 'KAGGLE_URL_BASE' not in set(os.environ.keys()): # kaggleのnotebook上では学習しない train = load_data(DATA_DIR + 'train.csv') train = preprocessing(train) training(train) # 推論 test = load_data(DATA_DIR + 'test.csv') test = preprocessing(test, is_train=False) submit_df = inference(test) submit_df.to_csv('submission.csv', index=False)
最後に
今回は私が行っているColabとVSCodeの運用方法についてまとめてみました。
もっといい感じの環境にできるのでは?と思っていたりするので、みなさんのColab Tipsも教えていただけると嬉しいです!
そして、本エントリが「Colabうまく使いこなせないなぁ」と思っていた人の一助になれば嬉しいです。
参考資料