
たかぱい(@takapy0210)です。
正月にGoogle CloudのDataformをゴニョゴニョ触っていたので、その備忘録を残しておこうと思います。
Dataformとは
SQL likeなコード(SQLX)でテーブルやビュー作成クエリを記述することで、テーブル間の依存関係を管理することができるデータモデリングツールです。同じようなツールではdbt*1が有名だと思います。
Dataformは、以前は独立したSaaS サービスでしたが、2020年12月にGoogle傘下に加わり、2023年6月6日にGAになりました。 cloud.google.com
2024/01 現在はBigQueryデータのモデリングツールとして、Google Cloud 管理コンソールから実行できるようになっています。
dbtとの違いは...?
Googleで検索するといくつか記事がヒットすると思いますが、
- dbtは機能が豊富でコミュニティも大きいが、学習コストがそこそこ高い
- Dataformは学習コストや運用コストは低い(Google Cloud上であれば無料で実行できる)が、dbtと比べると機能面で劣る
ということが言われているかと思います。
今回は個人開発で使用する目的なので、学習コストと運用コストが低いDataformを導入しました。
使用したデータ
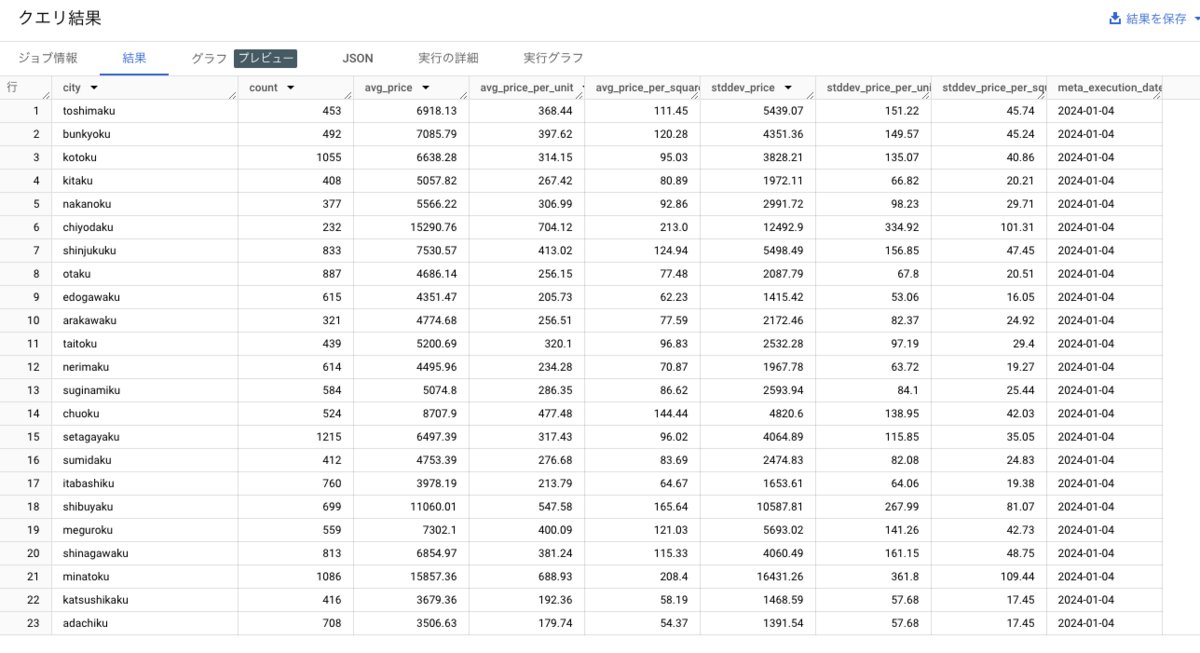
今回は僕が趣味で集めている都内のマンション情報のデータが既にBigQueryにあるので、そのRawデータから区ごとの平均坪単価などをDataformで集計して、データマートに自動的に保存するところまでやってみます。
実際に動かしてみる
以下のクイックスタート通りに動かしてみると、全体的な動きがある程度理解できるかと思います。
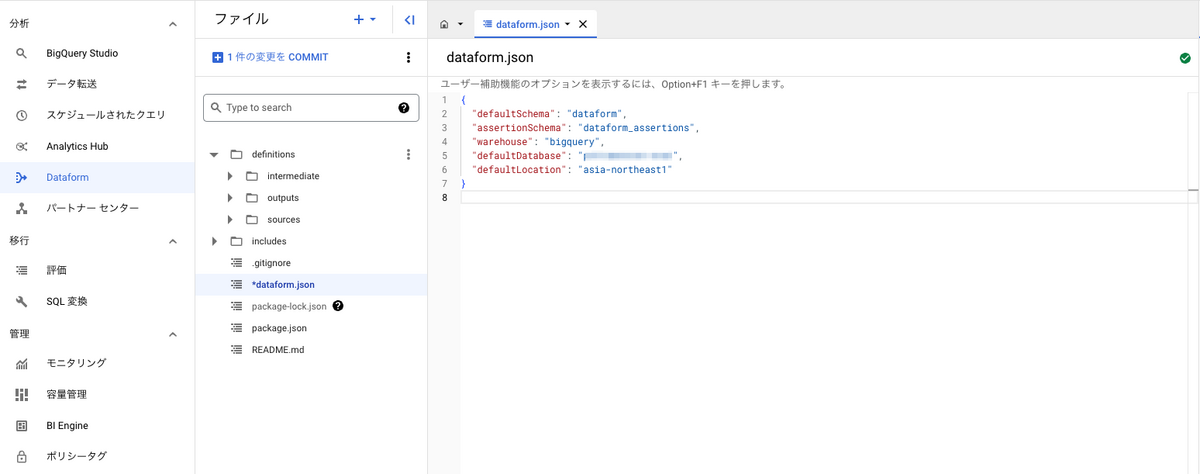
基本的な設定を記載する「dataform.json」
開発ワークスペースを初期化するとデフォルトでいくつかファイルが生成されますが、基本的な設定は dataform.json に記述されています。
{ "defaultSchema": "dataform", "assertionSchema": "dataform_assertions", "warehouse": "bigquery", "defaultDatabase": "hoge", "defaultLocation": "asia-northeast1" }
- defaultSchema: Dataform がアセットを作成する BigQuery データセットを指定する
- assertionSchema: Dataform がアサーション結果を含むビューを作成する BigQuery データセットを指定する
- warehouse: Dataform がアセットを作成する BigQuery へのポインタ。”bigquery” を指定する
- defaultDatabase: Dataform がアセットを作成する Google Cloud プロジェクトIDを指定する
- defaultLocation: デフォルトの BigQuery データセットのロケーションを指定する
Dataformのディレクトリ構成はどうするのが良いのか
買収前の従来のDataformのドキュメント*2には、definitions ディレクトリ配下に「Sources」、「Staging」、「Reporting」を用意することが推奨されていますが、Google Cloudのドキュメントには、ベストプラクティスとして以下のような構成が推奨されています。
sources: データソース宣言を格納intermediate: データ変換ロジックを格納outputs: 出力テーブルの定義を格納extras- 追加のファイルを格納(省略可)
今回はGoogle Cloudのベスプラに倣い、以下の構成で開発しました。
実際に記述するsqlxのコード
今回は以下の2つを追加しています。
- definitions/sources/mansion.sqlx
- definitions/outputs/day_aggregated_by_city.sqlx
definitions/sources/mansion.sqlx
ここではDataformで管理するテーブルを定義します。declarationを使ってテーブルを定義するのみで集計クエリなどは記載しません。
config {
type: "declaration",
database: "hoge",
schema: "lake",
name: "mansion"
}
Dataformのクエリで直接 SELECT * FROM project-id.dataset.table のように書くことはできますが、直接参照だとデータリネージで自動的に可視化されないので利用するテーブルはここで定義することをお勧めします。
declarationで定義しておくと SELECT * FROM ${ref(test_table)} という書き方で参照できます。
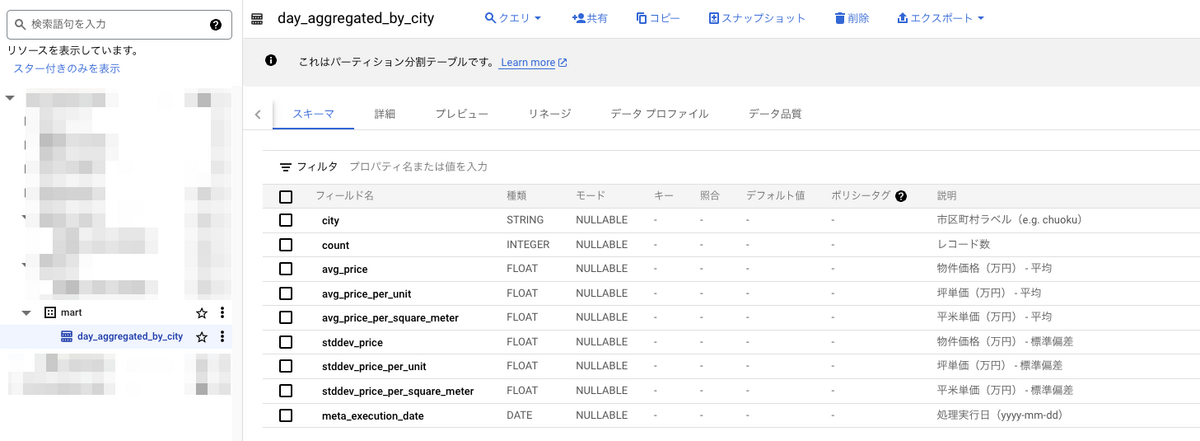
definitions/outputs/day_aggregated_by_city.sqlx
ここでは、データレイク(マンション情報)からデータを集計して、データマートに新しいテーブルを作成するクエリを定義します。
前述した通り、前提となるテーブルを「${ref("mansion")} 」という記法で参照できます。Dataform におけるテーブル間の依存関係管理はこれを書くだけでOKです。
パーティションやクラスタ*3の指定も configで行えます。
config {
type: "table",
database: "hoge",
schema: "mart",
columns: {
city: "市区町村ラベル(e.g. chuoku)",
count: "レコード数",
avg_price: "物件価格(万円) - 平均",
avg_price_per_unit: "坪単価(万円) - 平均",
avg_price_per_square_meter: "平米単価(万円) - 平均",
stddev_price: "物件価格(万円) - 標準偏差",
stddev_price_per_unit: "坪単価(万円) - 標準偏差",
stddev_price_per_square_meter: "平米単価(万円) - 標準偏差",
meta_execution_date: "処理実行日(yyyy-mm-dd)",
},
bigquery: {
partitionBy: "meta_execution_date",
clusterBy: ["city"]
},
}
SELECT
city,
COUNT(*) AS count,
ROUND(AVG(price_yen/10000), 2) AS avg_price,
ROUND(AVG(price_per_unit/10000), 2) AS avg_price_per_unit,
ROUND(AVG(price_per_square_meter/10000), 2) AS avg_price_per_square_meter,
ROUND(STDDEV(price_yen/10000), 2) AS stddev_price,
ROUND(STDDEV(price_per_unit/10000), 2) AS stddev_price_per_unit,
ROUND(STDDEV(price_per_square_meter/10000), 2) AS stddev_price_per_square_meter,
meta_execution_date,
FROM
${ref("mansion")}
WHERE
0 = 0
AND city IS NOT NULL
GROUP BY
city,
meta_execution_date
ここまでで、手動で新規テーブルを作成する準備は終わりです。コンソール上から手動実行すれば、BigQueryの mart 配下にテーブルができます。
スケジュール実行する
以下の手順に沿って設定し、自動化を行います。
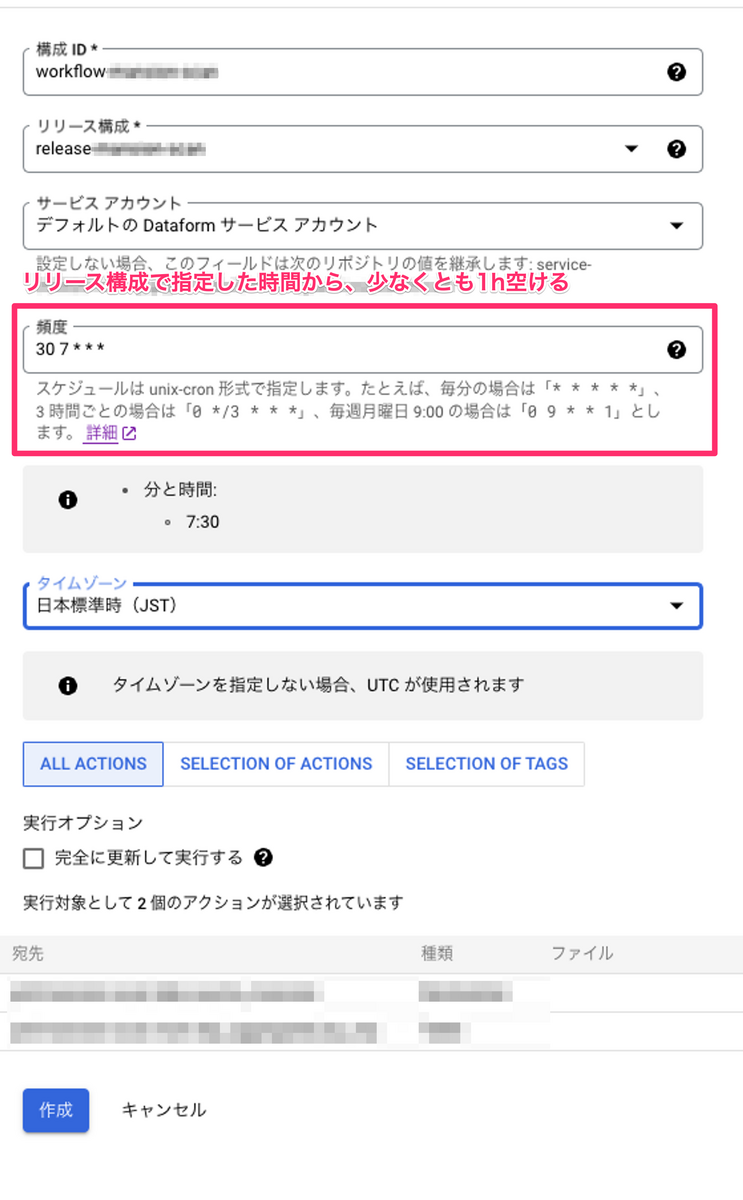
手順は大きく分けて「リリース構成」の作成と、「ワークフロー構築」の2ステップあります。
リリース構成とは、リポジトリを定期的にコンパイルしてリリースする頻度を指定するものです。
ワークフロー構築とは、実際に動くワークフローを指定するものです。
注意点として、公式ドキュメント*4にも記載されているように、リリース構成で指定した時間より、ワークフロー構築で指定する実行時間を、最短でも1h開けておく必要があるようです。
Dataform が対応するリリース構成で最新のコンパイル結果を確実に実行するには、コンパイル結果の作成時刻とスケジュールされた実行時刻の間に少なくとも 1 時間の間隔を設けます。
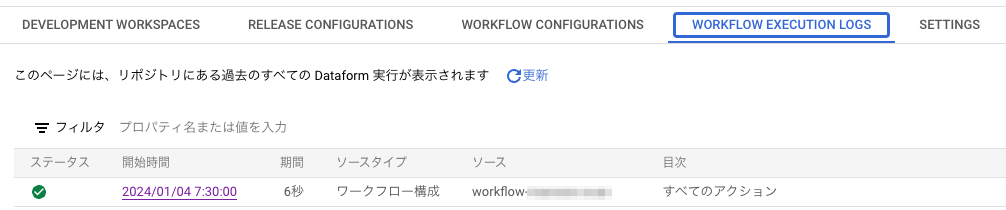
設定後、時間が過ぎると正しく動いていることが確認できました。
ワークフロー実行のログも、コンソール上から確認できます。
Githubと連携してコード管理する
最後にGithubとの連携を行い、コードをリポジトリで管理できるようにします。
こちらも公式ドキュメントが出ているので、基本的にはこの通りに設定すれば問題なく動くと思います。
おわりに
触ってみた感じ、WebUIでの開発環境がとっつきやすく、自動フォーマットもボタン1つで行なってくれるので開発効率は良さそうに感じました。
増分モデルなども簡単に実装できそうなので、この辺もいじっていきたいと思います。